Method
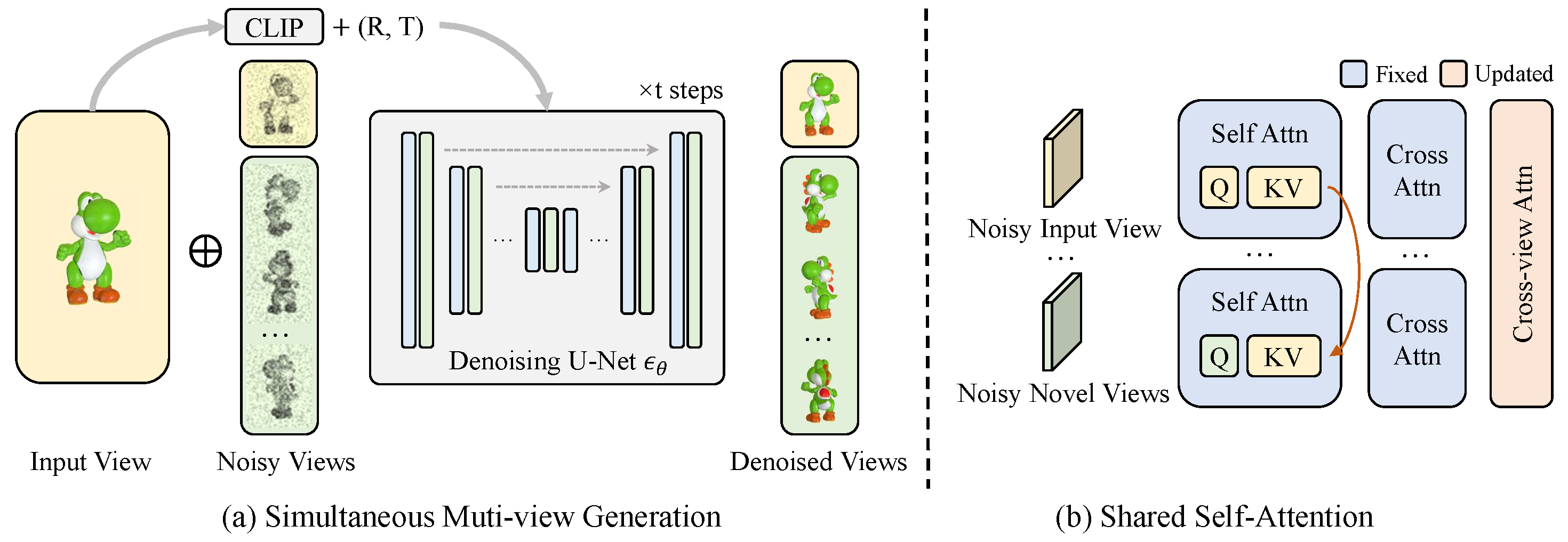
(a) At the training stage, multiple noisy views concatenated (denoted as ⊕) with the input view are fed into the denoising U-Net simultaneously, conditioned on the CLIP embedding of the input view and the corresponding poses. For sampling, views are denoised iteratively from the normal distribution through the U-Net. (b) In the shared self-attention layer, all views query the same key and value from the input view, which provides detailed spatial layout information for novel view synthesis. The input view and related poses are injected into the model by the cross-attention layer, and synthesized views are further aligned via the cross-view attention layer.